前端框架
慈善捐赠管理
腾讯云
调用
pycharm
#产品思维
系统
swoole
健身私教预约系统
离线仿真项目
委托传值
iphone
flutter
Semaphore
Java中的File类
File的构造方法
论文
下载视频方法
三星线刷
文件挂载
lxml
2024/4/20 7:58:39
Python lxml库 爬取问答问题, 并通知新问题
在问答的一个版块, 如果有人发布了新的问题, 问答不会进行通知。 为了使更多提问者的问题能得到即时、快速的回答,编写了爬取问题标题程序, 用于在新问题发布时, 回答者能得到即时的通知。 目录1.下载页面2.解析XPath3.自动通知新问题1.下载页面
使用requests库的g…
Python中使用Xpath
XPath在Python的爬虫学习中,起着举足轻重的地位,对比正则表达式 re两者可以完成同样的工作,实现的功能也差不多,但XPath明显比re具有优势,在网页分析上使re退居二线。
XPath介绍: 是什么? 全称…
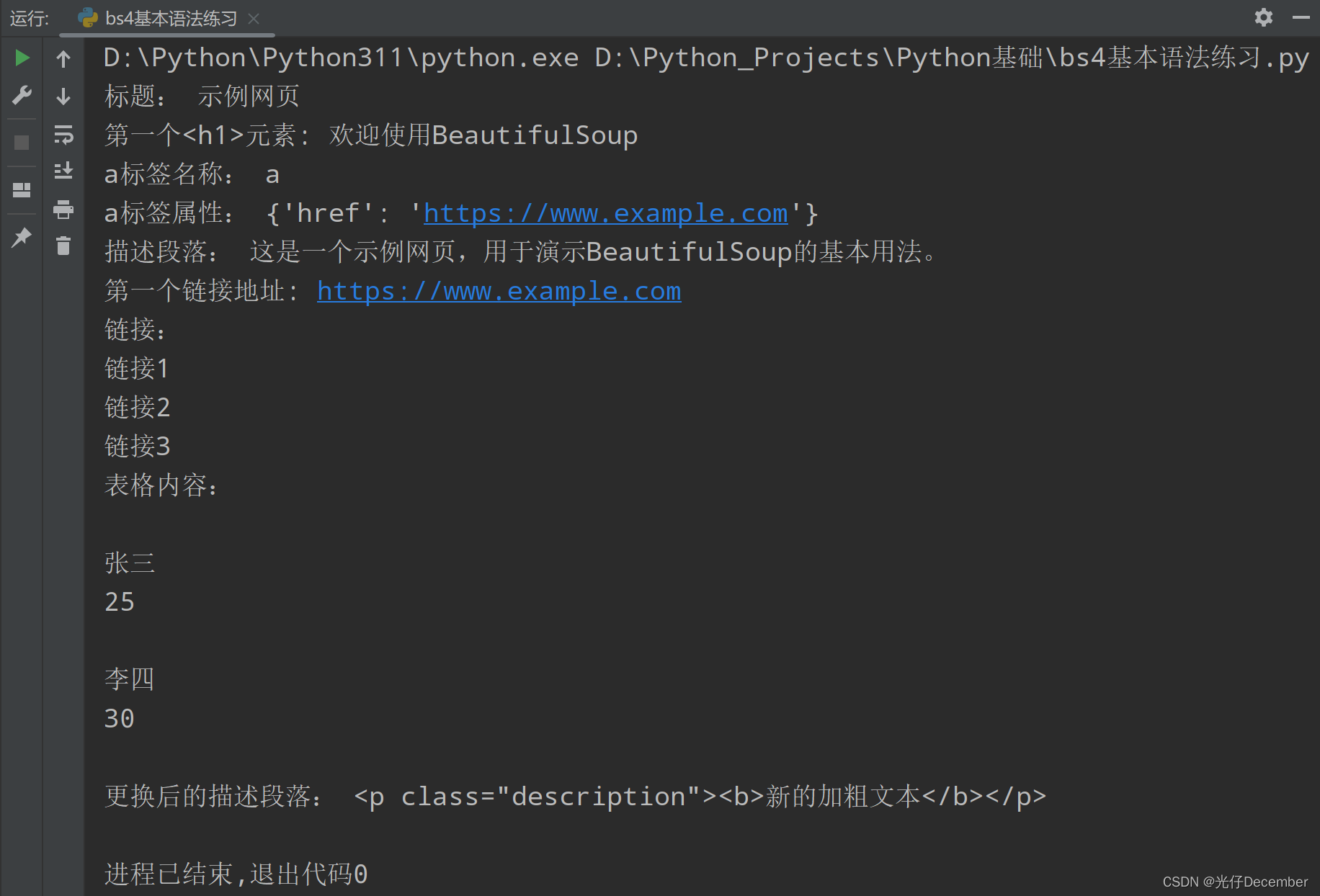
【Python从入门到进阶】32、bs4的基本使用
接上篇《31、使用JsonPath解析淘票票网站地区接口数据》 上一篇我们介绍了如何使用JSONPath来解析淘票票网站的地区接口数据,本篇我们来学习BeautifulSoup的基本概念,以及bs4的基本使用。
一、BeautifulSoup简介
1、bs4基本概念
BeautifulSoup是一个P…

爬虫(三)lxml+requests(豆瓣Top250电影)
回家之后就不想学习了…
这次用的是lxml库,因为听说比起BeautifulSoup它的速度更快,然后就想了解一下。(全部的代码在最下面)
import库
from lxml import etree
import requests
import json
# from time import sleep
这是要…

用python爬取基金网信息数据,保存到表格,并做成四种简单可视化。(爬虫之路,永无止境!)
用python爬取基金网信息数据,保存到表格,并做成四种简单可视化。(爬虫之路,永无止境!)
上次 2021-07-07写的用python爬取腾讯招聘网岗位信息保存到表格,并做成简单可视化。 有的人留言问我&…
python:lxml 读目录.txt文件,用 xmltodict 转换为json数据,生成jstree所需的文件
请参阅:java : pdfbox 读取 PDF文件内书签
请注意:书的目录.txt 编码:UTF-8,推荐用 Notepad 转换编码。
pip install lxml ;
lxml-5.1.0-cp310-cp310-win_amd64.whl (3.9 MB)
pip install xmltodict ;
lxml 读目录.txt文件&…
使用lxml解析本地html文件报错?
场景说明
使用 lxml 中的 parse 方法读取本地 html 文件报错,遇到这种问题该怎么解决呢?
from lxml import etreeresponse etree.parse(test.html)
tr_list response.xpath(//table[class"list-table"]/tbody/tr[not(id)][position()>1…
【小沐学Python】网络爬虫之lxml
文章目录 1、简介2、安装3、基本功能3.1 lxml.etree3.2 解析HTML网页3.3 读取并解析HTML文件3.4 提取所有a标签内的文本信息3.5 树迭代3.6 序列化3.7 元素以字典的形式携带属性3.8 元素包含文本 4、代码测试4.1 lxml解析网页4.2 使用xpath获取所有的文本4.3 使用xpath获取 clas…

Scrapy与分布式开发(2.3):lxml+xpath基本指令和提取方法详解
lxmlxpath基本指令和提取方法详解
一、XPath简介
XPath,全称为XML Path Language,是一种在XML文档中查找信息的语言。它允许用户通过简单的路径表达式在XML文档中进行导航。XPath不仅适用于XML,还常用于处理HTML文档。
二、基本指令和提取…
python:lxml 生成思维导图 Freemind(.mm)文件
请参阅:从PDF中提取目录 或者 java : pdfbox 读取 PDF文件内书签
pip install lxml ;
lxml-5.1.0-cp310-cp310-win_amd64.whl (3.9 MB)
读目录.txt文件,使用 lxml 生成思维导图 Freemind(.mm)文件
编写 txt_etree_mm.py 如下…
4-爬虫-selenium(等待元素加载、元素操作、操作浏览器执行js、切换选项卡、前进后退异常处理)、xpath、动作链
1 selenium等待元素加载 2 selenium元素操作 3 selenium操作浏览器执行js 4 selenium切换选项卡 5 selenium前进后退异常处理 6 登录cnblogs 7 抽屉半自动点赞 8 xpath 9 动作链 10 自动登录12306
上节回顾
# 1 bs4 解析库---》xml(html)-遍历文档树-属性 文本 标签名-搜索文…

XPath判断当前选中节点的元素类型 Python lxml判断当前Element的元素类型 爬虫爬取页面分元素类型提取纯文本
背景&前言
不知道你们做爬虫的时候,有没有碰到和我一样的情况:将页面提取成纯文本的时候,由于页面中各种链接、加粗字体等,直接提取会造成结果一坨一坨的,非常不规整。有时候还要自己对标题等元素进行修改&#x…
Python+requests+lxml爬取豆瓣电影短评
# 1-数据 -- requests
"""
豆瓣指定电影短评---10页1-下载页面2-检索数据3-数据存储
"""
import requests
from lxml import html
def download(url):code requests.get(url).text # strcode html.fromstring(code)return codedef getvalues(…

用python实现csdn博主全部博文下载,html转pdf,有了学习的电子书了。。。(附源码)
用python实现csdn博主全部博文下载,html转pdf,有了学习的电子书了。。。(附源码)
我们学习编程,在学习的时候,会有想把有用的知识点保存下来,我们可以把知识点的内容爬下来转变成pdf格式&#…

Python lxml库 提取并保存网页正文部分
有时候, 看见一篇网页, 不知道怎样离线保存。使用浏览器的保存网页功能, 又会保存下许多无用的信息, 如广告等其他部分。 为解决这个问题, 本程序使用requests库获取网页源代码, 使用re模块及lxml库提取内容、CSS样式, 提取网页的正文部分。 目录1.下载页面2.获取文章对应的标签…

Python使用lxml解析XML格式化数据
Python使用lxml解析XML格式化数据 1. 效果图2. 源代码参考 方法一:无脑读取文件,遇到有关键词的行再去解析获取值 方法二:利用lxml等库,解析格式化数据,批量获取标签及其值
这篇博客介绍第2种办法,以菜鸟教…
Python3 HTML数据解析(lxml/BeautifulSoup/JsonPath)
Python3 HTML数据解析(lxml/BeautifulSoup/JsonPath) 本文由 Luzhuo 编写,转发请保留该信息. 原文: https://blog.csdn.net/Rozol/article/details/79968795 以下代码以Python3.6.1为例 Less is more! lxml
#!/usr/bin/env python
# codingutf-8
__author__ Luzhuo
__date…